- Published on
Notes on Regression - Singular Vector Decomposition
- Authors
- Name
Here's a fun take on the OLS that I picked up from The Elements of Statistical Learning. It applies the Singular Value Decomposition, also known as the method used in principal component analysis, to the regression framework.
Singular Vector Decomposition (SVD)
First, a little background on the SVD. The SVD could be thought of as a generalisation of the eigendecomposition. An eigenvector v of matrix is a vector that is mapped to a scaled version of itself:
where is known as the eigenvalue. For a full rank matrix (this guarantees orthorgonal eigenvectors), we can stack up the eigenvalues and eigenvectors (normalised) to obtain the following equation:
where is an orthonormal matrix.
For the SVD decomposition, can be any matrix (not square). The trick is to consider the square matrices and . The SVD of the matrix is , where is a square matrix of dimension and is a square matrix of dimension . This implies that and can be seen to be the eigenvalue matrix of that square matrix. Similarly, the eigenvectors of forms the columns of while is the square root of the eigenvalues of either matrix.
In practice, there is no need to calculate the full set of eigenvectors for both matrices. Assuming that the rank of is k, i.e. it is a long matrix, there is no need to find all n eigenvectors of since only the elements of the first k eigenvalues will be multiplied by non-zero elements. Hence, we can restrict to be a matrix and let be a matrix.
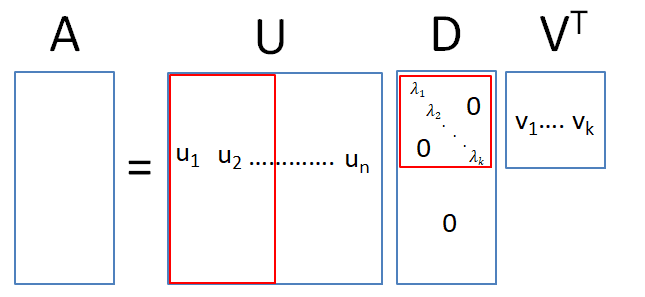
Applying the SVD to OLS
To apply the SVD to the OLS formula, we re-write the fitted values, substituting the data input matrix with its equivalent decomposed matrices:
where the third to fourth line comes from the fact that is a matrix with the square root of the eigenvalues on the diagonal, and is a square diagonal matrix. Here we see that the fitted values are computed with respect to the orthonormal basis .1
Link to the ridge regression
The ridge regression is an OLS regression with an additional penalty term on the size of the coefficients and is a popular model in the machine learning literature. In other words, the parameters are chosen to minimalise the penalised sum of squares:
The solution to the problem is given by: . Substituting the SVD formula into the fitted values of the ridge regression:
where is a n-length vector from the columns of . This formula makes the idea of regularisation really clear. It shrinks the predicted values by the factor . Moreover, a greater shrinkage factor is applied to the variables which explain a lower fraction of the variance of the data i.e. lower . This comes from the fact that the eigenvectors associated with a higher eigenvalue explain a greater fraction of the variance of the data (see Principal Component Analysis).
The difference between how regularisation works when one uses the Principal Component Analysis (PCA) method vs the ridge regression also becomes clear with the above formulation. The PCA approach truncates variables that fall below a certain threshold, while the ridge regression applies a weighted shrinkage method.
Footnotes
Doing a QR decomposition will also give a similar set of results, though the orthogonal bases will be different. ↩