- Published on
Progressively Updating UI with FastAPI and Streamed Structured Responses
- Authors

- Name
- Timothy Lin
- @timlrxx
Almost a year ago, I wrote about various approaches to generating structured objects from large language models (LLMs) and the advantages of doing so. Since then, support for structured output has grown significantly, and many model providers, including OpenAI, Anthropic, and Google, as well as open-source LLMs and inference frameworks like Mistral, Llama3, and Ollama, have added support for JSON output and tool usage.1
In addition to the increased support for structured output, numerous client libraries have been released to improve the developer experience of using these features. One of the most notable ones in the Node.js ecosystem is Vercel's AI SDK, which allows for easy integration of LLMs into web applications by providing a developer friendly API for interacting with LLMs on the backend and useful hooks to speed up development on the frontend. A particularly interesting feature is the ability to stream partially structured objects from the backend to the frontend, which can be used to progressively update the UI as an LLM streams a structured response.
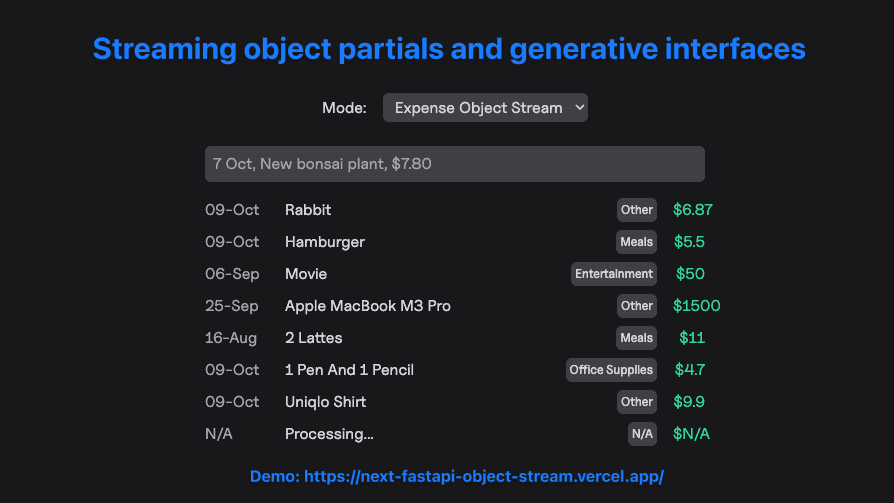
Recently, I decided to take a deeper look at how this streaming functionality was accomplished and wrote my own version using Python's FastAPI framework. Here's the demo application which uses the backend with a static Next.js application, similar to Vercel's example. The demo features 3 different approaches to stream text and objects from the backend to the frontend:
- Text stream with Vercel AI SDK useChat hook
- Object stream as text with useObject hook
- Partial JSON object stream with a custom hook implementation
For the source code, check out the Github Repo.
Table of Contents
Text Streams
Corresponding backend code and frontend chat interface.
Text streams are fairly common and there are multiple good resources on how to implement them, such as Afterward Tech's post on FastAPI and SSE and [Stefan Krawczyk's post on building a streaming agent with Burr, FastAPI and React]. On the backend the data is sent in a series of chunks, which the frontend client listens for and updates the UI accordingly.
With a FastAPI backend, we can use the StreamingResponse wrapper or alternatively Starlette's EventSourceResponse to stream the response. Both use the chunked transfer encoding to send the data but Starlette's EventSourceResponse adheres to the Server-Sent Events (SSE) protocol.2. On the client side, we can handle SSE with the EventSource API as shown in Afterward Tech's post or fetch and parse the chunks manually as shown in Stefan's post. Alternatively, we can use a library like Vercel's AI SDK to handle the stream.
In my demo, I used the StreamingResponse wrapper to stream the output from my Simple AI Agents library:
@app.post("/api/text_stream")
async def query(request: Request):
body = await request.json()
messages = body.get("messages")
prompt = messages[-1]["content"]
def stream_text(prompt: str):
"""Generate the AI model response and stream it."""
sess = ChatLLMSession(llm_options=llm_provider)
stream = sess.stream(prompt)
for chunk in stream:
yield chunk["delta"]
response = StreamingResponse(stream_text(prompt))
response.headers["x-vercel-ai-data-stream"] = "v1"
return response
The only notable aspect here is the x-vercel-ai-data-stream header which is required for the Vercel AI SDK to recognize the stream. On the frontend, we can use the useChat hook from the AI SDK with steamProtocol set to text to handle the stream and specify the corresponding backend API endpoint to initiate the stream:
import { useChat } from "ai/react";
const { messages, input, handleInputChange, handleSubmit, isLoading } =
useChat({
api: api,
onError: (e) => {
toast.error(`Failed to send message: ${e.message}`);
},
streamProtocol: "text",
});
Object Stream as Text
Corresponding backend code and frontend object stream interface.
Object streams are slightly more complex as we need to handle the parsing of the object on the frontend. I decided to see how we could use the useObject hook since it is designed to handle object streams and allows specifying a Zod schema to validate the object. This is a bit more complicated than I initially thought as the hook expects a text stream but the backend was sending Partial Pydantic Responses courtesy of the Instructor package.
The solution I came up with was to convert the object stream to a text stream on the backend that can be parsed by the useObject hook. Here's the pydantic_to_text_stream function that handles this logic:3
def pydantic_to_text_stream(
stream: Iterator[BaseModel], mode: Literal["full", "delta"] = "delta"
) -> Iterator[str]:
"""
Converts a stream of Pydantic models to a stream of JSON strings,
outputting either the full matching prefix or only the incremental difference
between consecutive streams with changes.
Args:
stream (Iterator[BaseModel]): An iterator yielding Pydantic model instances.
mode (Literal['full', 'delta']): The output mode.
'full' returns the full matching prefix (default).
'delta' returns only the incremental difference.
Yields:
str: JSON string representation of the diff between consecutive Pydantic models.
"""
json_history = []
last_output = ""
def get_matching_prefix(s1: str, s2: str) -> str:
"""Return the matching prefix of two strings."""
for i, (c1, c2) in enumerate(zip(s1, s2)):
if c1 != c2:
return s1[:i]
return s1 # If one string is a prefix of the other, return the shorter one
for model in stream:
# Convert the Pydantic model to a JSON string
new_json = json.dumps(model.model_dump(exclude_unset=True))
# If this is not the first item and the new JSON is not in the history
if json_history and new_json not in json_history:
# Get the matching prefix with the last JSON in history
diff = get_matching_prefix(json_history[-1], new_json)
# Determine the output based on the mode
if mode == "full":
output = diff
else:
output = diff[len(last_output) :]
if output:
yield output
last_output = diff
# Update the JSON history
json_history.append(new_json)
# Ensure we output the last stream if it's different from the last output
if json_history and json_history[-1] != last_output:
if mode == "full":
yield json_history[-1]
else:
yield json_history[-1][len(last_output) :]
We can use this function to wrap the Pydantic stream and convert it to a text stream that can be parsed by the useObject hook:
@app.post("/api/object_stream")
async def query(request: Request):
body = await request.json()
expense = body.get("expense")
prompt = f"Please categorize the following expense: {expense}"
def stream_object(prompt: str):
"""Generate the AI model response and stream it."""
sess = ChatLLMSession(llm_options=llm_provider)
stream = sess.stream_model(prompt, response_model=ExpenseSchema)
for delta in pydantic_to_text_stream(stream, mode="delta"):
yield delta
response = StreamingResponse(stream_object(prompt))
response.headers["x-vercel-ai-data-stream"] = "v1"
return response
The function keeps track of the JSON history and yields the incremental difference between consecutive JSON strings. The full mode returns the full matching prefix while the delta mode returns only the incremental difference. In my initial implementation, I only compared the current JSON string with the last JSON string in the history. However, this could lead to certain errors where the Pydantic partial is not yet finished and reverted back to a previous state, resulting in the client throwing an error. To fix this, we check if the current JSON string is actually updated and only yield the difference if it is.
A nice benefit of this approach is that it reduces the amount of data sent over the wire, as we only send the incremental difference that we are sure has changed, though there's a very slight (but arguably negligible) overhead since it requires an additional confirmation step to ensure the JSON string is actually updated.
On the frontend, we define an Expense type and directly use the useObject hook to handle the stream:
const [expenses, setExpenses] = useState<Expense[]>([]);
const { submit, isLoading, object } = experimental_useObject({
api: api,
schema: expenseSchema,
onFinish({ object }) {
if (object != null) {
setExpenses((prev) => [object.expense, ...prev]);
setInput("");
}
},
onError: (e) => {
toast.error(`Failed to submit expense: ${e.message}`);
},
});
Since expenses is automatically updated with new changes, we can directly use it to render the UI, and the component will appear to update in real-time as the object stream is received.
<div className="flex flex-col gap-2 h-full items-center">
{isLoading && object?.expense && (
<div className="opacity-50">
<ExpenseView expense={object.expense} />
</div>
)}
{expenses.map((expense) => (
<ExpenseView key={`${expense.details}`} expense={expense} />
))}
</div>
Partial JSON Object Stream
Corresponding backend code and frontend streaming interface with a custom hook.
What if we wanted to stream partial JSON objects to the frontend without first having the server convert them to text deltas? This would allow us to directly use the Pydantic partial objects at the price of sending over more data and having the frontend handle the parsing.
The backend would look pretty straightforward, and we would directly dump the Pydantic model to JSON and stream it:
@app.post("/api/stream_object_json")
async def query(request: Request):
body = await request.json()
expense = body.get("expense")
prompt = f"Please categorize the following expense: {expense}"
def stream_object_json(prompt: str):
"""Generate the AI model response and stream it."""
sess = ChatLLMSession(llm_options=llm_provider)
stream = sess.stream_model(prompt, response_model=Expense)
for delta in stream:
result = delta.model_dump_json()
yield result
response = StreamingResponse(stream_object_json(prompt))
response.headers["x-vercel-ai-data-stream"] = "v1"
return response
On the frontend, we now need to parse the partial JSON objects. This means that we can no longer use the useObject hook and would need to write a custom hook to handle the stream. Here's my useStreamJson hook that handles the stream and parses the partial JSON objects:
import { useState, useCallback } from "react";
interface StreamJsonOptions<T> {
url: string;
method?: "GET" | "POST";
headers?: Record<string, string>;
body?: any;
onChunk?: (chunk: T) => void;
}
export function useStreamJson<T>() {
const [isLoading, setIsLoading] = useState(false);
const [error, setError] = useState<Error | null>(null);
const streamJson = useCallback(
async ({
url,
method = "POST",
headers = {},
body,
onChunk,
}: StreamJsonOptions<T>) => {
setIsLoading(true);
setError(null);
try {
const response = await fetch(url, {
method,
headers: {
"Content-Type": "application/json",
...headers,
},
body: body ? JSON.stringify(body) : undefined,
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let buffer = "";
while (reader) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
let startIndex = 0;
while (true) {
const endIndex = buffer.indexOf("}", startIndex);
if (endIndex === -1) break;
try {
const jsonStr = buffer.slice(startIndex, endIndex + 1);
const parsedChunk = JSON.parse(jsonStr);
if (parsedChunk && onChunk) {
onChunk(parsedChunk as T);
}
startIndex = endIndex + 1;
} catch (error) {
startIndex++;
}
}
buffer = buffer.slice(startIndex);
}
} catch (error) {
setError(error as Error);
} finally {
setIsLoading(false);
}
},
[]
);
return { streamJson, isLoading, error };
}
The decoding logic is a bit more complex as we need to handle the case where the JSON object is split across multiple chunks. We keep track of the buffer and parse the JSON objects as they are received. The hook also allows for an onChunk callback to handle the parsed JSON object.
On the frontend, we can use the useStreamJson hook to read the stream and update the UI accordingly:
const [expenses, setExpenses] = useState<Expense[]>([]);
const { streamJson, isLoading, error } = useStreamJson<Expense>();
const handleSubmit = async (event: React.FormEvent<HTMLFormElement>) => {
...
await streamJson({
url: api,
method: "POST",
body: { expense: input.value },
onChunk: (chunk) => {
setExpenses((prev) => {
const newExpenses = [...prev];
newExpenses[newExpenses.length - 1] = {
...newExpenses[newExpenses.length - 1],
...chunk,
} as Expense;
return newExpenses;
});
},
});
...
};
The Possibilities of Streaming User Interfaces
In this post, I explored three different approaches to streaming data from a Python backend to a Next.js frontend, using FastAPI and Vercel's AI SDK, and compared the differences between two approaches to stream objects to create generative interfaces. Feel free to explore the demo and the source code to dive deeper into the implementation details.
One of the things that intrigues me with the rise of generative AI is the new user experiences and modes of interaction that it would allow. By leveraging the real-time capabilities of streaming structured data to the frontend, we can create personalized user journeys that adapt to a user's input and preferences. This could take the form of minor UX improvements, like the expense categorization example we explored, where the user can see the model's output in real-time as they input their expense details. The instant feedback and the ability to see the model's output can make the interaction feel more engaging and transparent.
However, the possibilities extend far beyond simple form interactions. Imagine a streaming dashboard that adapts to a user's queries and presents relevant data and insights in real-time. As the user explores different aspects of their data, the dashboard could dynamically generate visualizations, summarize key findings, and even suggest actions based on the patterns it detects. Taking it a step further, we could envision more creative (or perhaps dystopian) applications, like a generative news website that streams a personalized news feed based on a user's interests and preferences.
By leveraging the power of real-time data streams and adaptive models, we can create experiences that are more engaging, personalized, and valuable to users. As developers and designers, it's an exciting time to explore these possibilities and push the boundaries of what's possible.
Footnotes
Though there are notable differences between the approaches in terms of their effectiveness, especially for more complex parsing tasks and multiple tool calls. Nonetheless, this is still a significant step forward in terms of usability compared to 1 year ago. ↩
Ab Hassanein explains the differences between the two in his blog post. ↩
I published the function and an asynchronous version of it in the Simple AI Agents library so one could simply import it by running
from simple_ai_agents.utils import pydantic_to_text_streamand use it in a project. ↩